
[딥러닝 첫걸음]간단한 모델 만들기
Tieck
·2021. 9. 4. 18:58
Kaggle notebook을 사용하여 간단한 모델을 만들었다.
입문자에게 예제로 자주 쓰이는 CIFAR 데이터 셋을 사용하였다.
CIFAR100 dataset은 훈련 속도가 오래걸리기 때문에 CIFAR10 datset을 선택했다.
데이터 셋 이름 + 라벨의 개수로 CIFAR10은 label이 10개인 데이터로 구성된 비교적 작은 규모의 데이터셋이다.
각 라벨당 6,000개의 이미지가 포함되어 총 60,000개의 이미지로 구성되었다.
기본적으로 training images 50,000개 , test image images 10,000개로 나뉘어 존재한다.

각 이미지는 (가로, 세로, 채널) = (32, 32, 3) 로 구성되었다.
* 채널에는 주로 색상의 개수가 포함된다.
RGB로 구성된 이미지는 (가로, 세로, 3)으로,
gray scale인 이미지는 (가로, 세로, 1)으로 표현한다.
gray scale의 경우 채널을 생략할 수도 있다.
데이터셋 다운로드 에러
Kaggle notebook에서 다음과 같은 오류가 발생했다.
Internet이 turn off 상태이기 때문에 CIFAR10 dataset의 온라인 다운로드가 안됐다.
Exception: URL fetch failure on https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz: None -- [Errno -3] Temporary failure in name resolution
해결책 : 프로그램의 Internet 연결 점검
(이번 케이스 에서는 Internet : turn on으로!)

전처리
함수화 / 입력 데이터의 형변환 (np->tensor) / one hot encoding /
import numpy as np
def get_preprocessed_ohe(img,label):
images = np.array(img,dtype=np.float32)
labels = np.array(label, dtype=np.float32)
#one hot encoding
oh_labels = to_categorical(labels)
return images, oh_labels
* 코드는 기본적으로 함수화했다.
함수형태로 코드를 만들면 많은 장점이 존재한다.
1. 동일한 처리가 필요할 때 반복 작업을 줄이고, 확실하게 동일한 처리 가능
2. 스크립트를 함수에 따라 직관적 이해 가능 (주로 기능을 함수로 구현 하였다.)
tensorflow는 전통적으로 tensor라는 자료형을 사용한다.
모델의 Input 레이어에서 np.float32 ->tf.float32의 묵시적 형변환이 일어난다.
따라서, 전처리 과정에서 입력 데이터의 자료형을 np.float32 변경해야한다.
- numpy : GPU 지원 X, only CPU
- Tensor : CPU & GPU
cpu 기반 연산은 SIMD 연산을 통해 병렬 연산을 수행한다.
Deep Learning 학습은 연산량이 매우 많아 CPU SIMD기반의 Numpy로는 감당할 수 없다.
그래서 GPU를 활용한 Tensor 연산을 수행한다.(CPU 역시 가능)
Numpy Array는 범용성, Tensor는 Deep Learning에 특화된 기능을 가진다.
프레임워크는 Tensorflow/Keras, Pytorch 등이 있다.
그후 라벨을 to_categorical 함수를 이용해 one hot encoding 하였다.
one hot encoding은 하나one 의 라벨만 hot (1), 나머지 라벨은 cold (0) 형태로 변환하는 것이다.
원핫인코딩을 하면 col의 수가 늘어난다.
단일 column 방식인 lable encoding에 비해 다중 column 방식인 one hot encoding은 컴퓨터의 기본 처리 방식인 병렬처리방식에 유리해서 더 빠를 것이라고 추측한다.
더 공부할 필요가 있다.
데이터 셋 분리
get_data()함수의 매개 변수인 validation이 True일 경우 train/val/test set으로 구분된다.
train set과 validation set의 비율은 test_size를 통해 설정할 수 있다.
def get_data(train_images,test_images,train_labels,test_labels,validation=False,test_size=0.2):
from sklearn.model_selection import train_test_split
if validation:
tr_images, val_images, tr_labels, val_labels = train_test_split(train_images,train_labels,test_size=test_size)
tr_images,tr_labels = get_preprocessed_ohe(tr_images,tr_labels)
val_images,val_labels = get_preprocessed_ohe(val_images,val_labels)
test_images,test_labels = get_preprocessed_ohe(test_images,test_labels)
return tr_images, val_images, test_images, tr_labels, val_labels, test_labels
else:
tr_images,tr_labels = get_preprocessing(tr_images,tr_labels)
test_images,test_labels = get_preprocessing(test_images,test_labels)
return tr_images, test_images, tr_labels, test_labels
구현 : 데이터 불러오기
함수화를 통해 데이터 다운로드 부터 전처리까지 간단하게 처리하고 결과를 출력했다.
from tensorflow.keras.datasets import cifar10
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
# validation set을 만들지 않는 경우
# tr_img,val_img,tr_label,val_label = train_test_split(train_images,train_labels,test_size=0.3)
tr_images, val_images, test_images, tr_labels, val_labels, test_labels = get_data(train_images, test_images,train_labels,test_labels,validation=True,test_size=0.3)
print(tr_images.shape)
print(val_images.shape)
print(test_images.shape)
print(tr_labels.shape)
print(val_labels.shape)
print(test_labels.shape)
출력 :

label이 one hot encoding 되었음을 확인

기본적인 합성곱 신경망(CNN) 모델 만들기
def model_create(INPUT_SIZE=32):
input_tensor = Input(shape=(INPUT_SIZE,INPUT_SIZE,3))
x = Conv2D(filters=100,kernel_size=3,padding='same',activation='relu')(input_tensor)
x = Conv2D(filters=100,kernel_size=3,padding='same',activation='relu')(x)
x = Conv2D(filters=100,kernel_size=3,padding='same',activation='relu',strides=1)(x)
x = Conv2D(filters=100,kernel_size=3,padding='same',activation='relu')(x)
x = Flatten()(x)
x = Dropout(0.5)(x)
output = Dense(10,activation='softmax')(x)
model = Model(inputs = input_tensor, outputs=output)
model.summary()
return model
INPUT_SIZE = 32
model = model_create(INPUT_SIZE)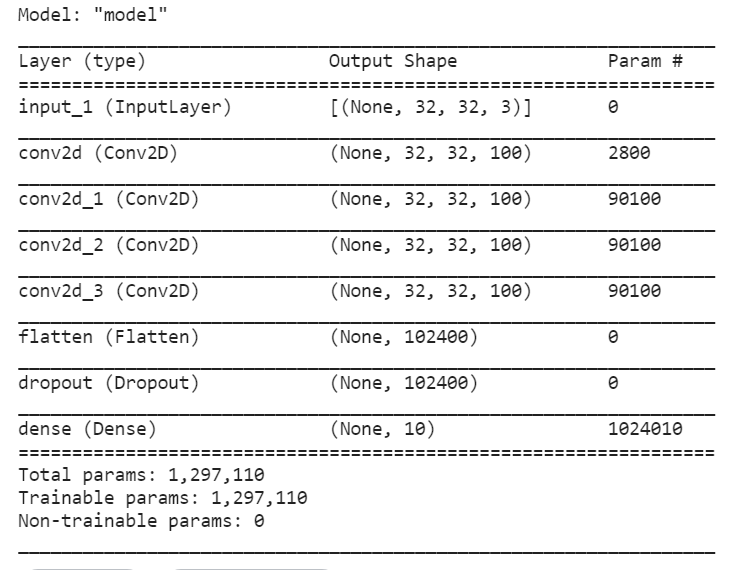

딥러닝은 신경망 Neural Network을 거처 원하는 결과가 도출되도록 가중치 weight를 조절한다.
학습은 오차 역전파 error backpropagation 방식으로 진행된다. (학습 과정은 다른 포스팅에서)
신경망은 여러 층 Layer로 구성된다.
합성곱 연산 Conv2D Layer
픽셀 Pixcel은 이미지에서 가장 작은 한 점을 표현하는 기본 단위이다.
이미지는 점의 집합이다. 그래서 이미지는 픽셀의 집합으로 표현된다.
대부분의 온라인상의 이미지는 (가로, 세로, 채널)인 픽셀의 그룹으로 표현한다.
기본적으로 CIFAR dataset의 이미지는 가로 32개, 세로 32개, 색깔 3개(RGB) 총 32 * 32 * 3개의 픽셀로 구성된다.
해당 픽셀을 numpy array에 담아 (32, 32, 3)인 np.array로 표현하였다.
합성곱 연산은 각 이미지 개별 채널과 Kernel Matrix를 행렬 곱 matrix product하는 것이다.
방법은 다음 이미지와 같다.

Kernel Matrix는 딥러닝의 핵심으로 다양한 논문을 통해 발전하고 있다.
Dense Layer
Dense layer의 입력 형태는 1차원이다.
그래서 Flatten()을 통해 (bacth 제외) 3차원인 데이터를 1차원으로 만들었다.
batch는 이미지의 로딩과 학습 시간을 단축시키기 위해 전체 데이터 셋을 N개로 나눈 것 중 한 묶음을 의미한다.
shape의 None은 따로 설정하지 않으면 tensorflow/keras framework에서 적절하게 설정한다.
Dense layer는 직접적인 계산에 이용 될 수 있다. 하지만 출력층Output layer 에 주로 이용된다.
CIFAR10 데이터 셋의 라벨 개수는 10개이기 때문에 filter를 10개로 설정하였다.
활성화 함수Activation function 은 여러개의 class 중 1개의 class를 결정multi-class classification 하는 softmax activation을 사용했다.
Dropout Layer
파라미터의 수가 많을 경우 연산 속도가 느려진다. 특히, 훈련용 데이터셋에 과적합overfitting 되는 경우 성능에 악영향을 미치는 경우도 있다. 따라서 Dropout layer에서 특정한 비율로 파라미터를 제거한다.
성능



테스트 결과 손실 : 2.0158, 정확도 : 0.6149가 나왔다. 많은 개선의 여지가 있다.
특히 validation set의 경우 정확도는 0.6 근처에서 증가하지 않고, 손실은 꾸준히 증가하는 경향이 드러난다.
optimizer, callback, data augmentaion 등을 적용하여 다음 글에서 발전시켜보자.
Reference
CIFAR-10 and CIFAR-100 datasets (toronto.edu)
CIFAR-10 and CIFAR-100 datasets
< Back to Alex Krizhevsky's home page The CIFAR-10 and CIFAR-100 are labeled subsets of the 80 million tiny images dataset. They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. The CIFAR-10 dataset The CIFAR-10 dataset consists of 60000
www.cs.toronto.edu
1) 합성곱 신경망(Convolution Neural Network) - 딥 러닝을 이용한 자연어 처리 입문 (wikidocs.net)
1) 합성곱 신경망(Convolution Neural Network)
합성곱 신경망(Convolutional Neural Network)은 이미지 처리에 탁월한 성능을 보이는 신경망입니다. 이 책의 주제는 이미지 처리가 아니라 자연어 처리이기 ...
wikidocs.net
https://stackoverflow.com/questions/52067833/how-to-plot-an-animated-matrix-in-matplotlib
How to plot an animated matrix in matplotlib
I need to do step by step some numerical calculation algorithms visually, as in the figure below: (gif) Font How can I do this animation with matplotlib? Is there any way to visually present these
stackoverflow.com
'딥러닝' 카테고리의 다른 글
| [딥러닝첫걸음2]실전 모델의 뼈대 만들기 (0) | 2021.09.22 |
|---|


