
[문자열][programmers]이상한 문자 만들기
Tieck
·2021. 10. 5. 18:48
문제
문자열 s는 한 개 이상의 단어로 구성되어 있습니다. 각 단어는 하나 이상의 공백문자로 구분되어 있습니다. 각 단어의 짝수번째 알파벳은 대문자로, 홀수번째 알파벳은 소문자로 바꾼 문자열을 리턴하는 함수, solution을 완성하세요.
https://programmers.co.kr/learn/courses/30/lessons/12930
코딩테스트 연습 - 이상한 문자 만들기
문자열 s는 한 개 이상의 단어로 구성되어 있습니다. 각 단어는 하나 이상의 공백문자로 구분되어 있습니다. 각 단어의 짝수번째 알파벳은 대문자로, 홀수번째 알파벳은 소문자로 바꾼 문자열을
programmers.co.kr
이해
입력
- s : 한 개 이상의 단어로 구성된 문자열
각 단어는 하나 이상의 공백문자로 구분
출력
- 수정된 문자열
조건
- 문자열 전체의 짝/홀수 인덱스가 아니라, 단어(공백을 기준)별로 짝/홀수 인덱스를 판단해야합니다.
- 첫 번째 글자는 0번째 인덱스로 보아 짝수번째 알파벳으로 처리해야 합니다.
예시
| s | return |
| "try hello world" | "TrY HeLlO WoRlD" |
접근
- 단어 기준 짝/홀 수 인덱스 판단
- 단어 개수 : len(str.split())
- 짝수 : n % 2 ==0
- 홀수 : n % 2 ==1
- 대문자, 소문자 변환 : str.lower(), str.upper()
구현
try #1
채점 결과
정확성:
합계: / 100.0
def solution(s):
answer = []
word_list = s.split()
for word_idx in range(len(word_list)):
word = word_list[word_idx]
for chr_idx in range(len(word)):
changed_word = []
if chr_idx%2 == 0:
changed_word.append(word[chr_idx].upper())
print(changed_word)
else:
changed_word.append(word[chr_idx].lower())
print(changed_word)
answer.append(''.join(changed_word))
" ".join(answer)
return answer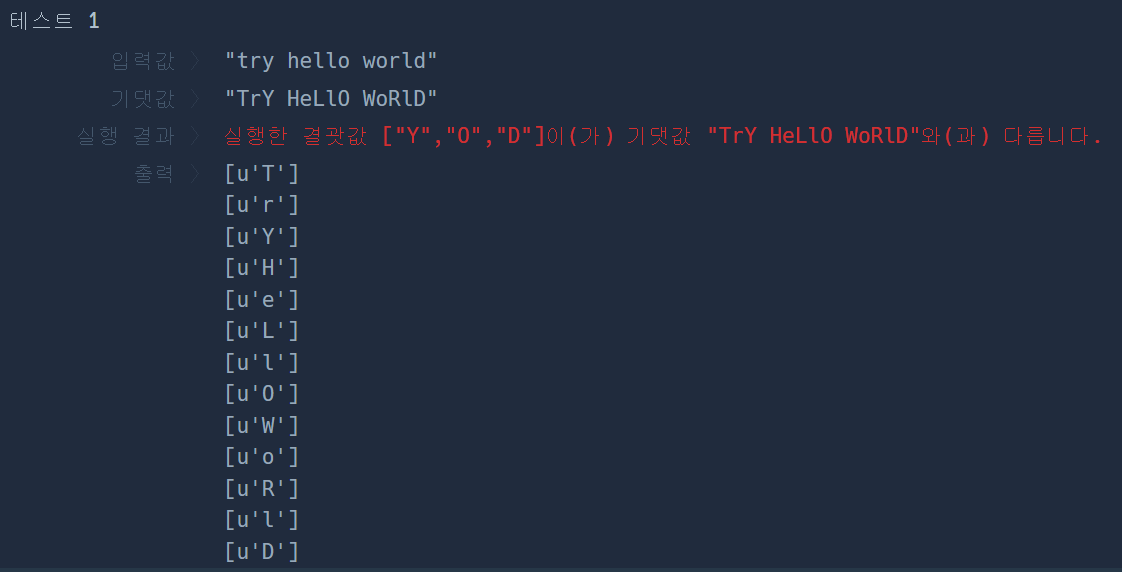
- idx로 접근 : 단어의 순서 / 각 단어에서 문자의 순서
- u'문자열' 꼴 : 유니코드, UTF-8의 표기법
- chr(u'문자열')로 문자열 형태로 변환
try #2
채점 결과
정확성:
합계: / 100.0
def solution(s):
answer = []
word_list = s.split()
for word_idx in range(len(word_list)):
word = word_list[word_idx]
for chr_idx in range(len(word)):
changed_word = []
if chr_idx%2 == 0:
changed_word.append(str(word[chr_idx].upper()))
print(changed_word)
else:
changed_word.append(str(word[chr_idx].lower()))
print(changed_word)
answer.append(''.join(changed_word))
" ".join(answer)
return answer

- 간단한 intent 문제
try #3
채점 결과
정확성: 31.3
합계: 31.3 / 100.0
def solution(s):
answer = []
word_list = s.split()
changed_word_list = []
for word_idx in range(len(word_list)):
word = word_list[word_idx]
changed_word = []
for chr_idx in range(len(word)):
if chr_idx%2 == 0:
changed_word.append(str(word[chr_idx].upper()))
# print(changed_word)
else:
changed_word.append(str(word[chr_idx].lower()))
changed_word_list.append(''.join(changed_word))
# print(answer)
answer = " ".join(changed_word_list)
return answer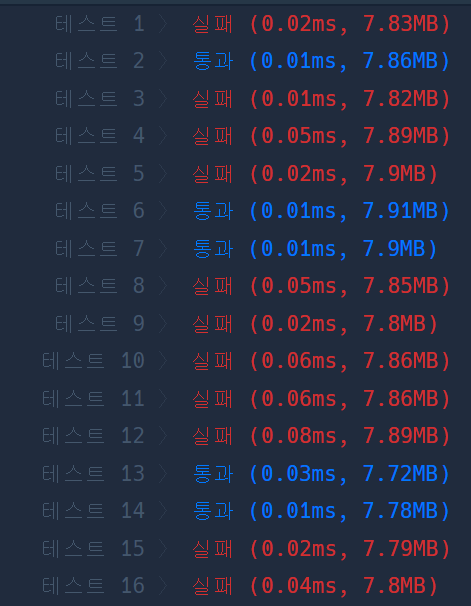
- 통과보다 실패가 더 많다.
- 메모리 제한, 시간 제한 때문은 아니다. (테스트 3, 7의 비교)
- 변수 이름 짓기 어렵다.
- 불필요한 변수를 선언해서 메모리를 사용하는 지 의심된다.
- 예외처리? 알파벳이 아닌 다른 입력이 섞여있을 수도 있다.
try #4
채점 결과
정확성: 31.3
합계: 31.3 / 100.0
def solution(s):
answer = []
word_list = s.split()
changed_word_list = []
for word_idx in range(len(word_list)):
word = word_list[word_idx]
changed_word = []
for chr_idx in range(len(word)):
#문자 검사
if word[chr_idx].isalpha():
if chr_idx%2 == 0:
changed_word.append(str(word[chr_idx].upper()))
# print(changed_word)
else:
changed_word.append(str(word[chr_idx].lower()))
else:
pass
changed_word_list.append(''.join(changed_word))
# print(answer)
answer = " ".join(changed_word_list)
return answer- 문자(알파벳) 검사 실시
- 결과는 try#3과 동일하다.
- 입력값은 전부 문자로 들어온다.
try #5
채점 결과
정확성: 100.0
합계: 100.0 / 100.0
def solution(s):
answer = []
word_list = s.split(" ")
changed_word_list = []
for word_idx in range(len(word_list)):
word = word_list[word_idx]
changed_word = []
for chr_idx in range(len(word)):
if word[chr_idx].isalpha():
if chr_idx%2 == 0:
changed_word.append(str(word[chr_idx].upper()))
# print(changed_word)
else:
changed_word.append(str(word[chr_idx].lower()))
else:
pass
changed_word_list.append(''.join(changed_word))
# print(answer)
answer = " ".join(changed_word_list)
return answer
- 각 단어는 <공백>으로 구분된다.
- str.split(" ")
- str.split의 default sep이 공백이 아니었다.

- 연속된 공백 -> 공백 하나로 취급
- 문자열의 앞, 뒤에 공백 포함 -> 결과에 포함하지 않음

None 단어 ('')를 단어로 취급하는 것은 이상하다. 단어의 기준에 더 부합하는 코드는 첫번째 코드라고 생각한다.
하.지.만
조건에 "한개 이상의 공백으로 구분" 되었다고 명시되어 있고, 입력한 "문자열"을 보존하여 조건에 맞춰 대,소문자를 변경해주는 것이 문제이므로, none seporator를 사용할 경우 출력 문자열의 길이가 축소되어 버린다. 그러니 본 문제에서는 두 번째 코드를 사용하는 것이 적절하다.
코드리뷰
문정승 외 3명
def solution(s):
return ' '.join([''.join([c.upper() if i % 2 == 0 else c.lower() for i, c in enumerate(w)]) for w in s.split(' ')])- 간결한 한줄코드
- 가독성을 생각했을 때 살짝 복잡한 것 같다.
- 변수를 추가로 선언하지 않고 만들었다. (배울점)
- 나는 changed_word / changed_word_list 2개의 리스트를 추가로 선언했다.
- list comprehension에 익숙해지자.
rhdudals0659
def toWeirdCase(s):
return " ".join(map(lambda x: "".join([a.lower() if i % 2 else a.upper() for i, a in enumerate(x)]), s.split(" ")))- 간결한 한줄코드
- 파이썬 스럽다. (map, lambda)
- 변수를 추가로 선언하지 않고 만들었다. (배울점)
- 구글의 파이썬 스타일 가이드에 따르면 값을 명시적(Explicitly) 비교하는 편이 좋다.
if not i % 10:
print("BAD CODE")
if i % 10 == 0:
print("GOOD CODE")
익명
def toWeirdCase(s):
res = []
for x in s.split(' '):
word = ''
for i in range(len(x)):
c = x[i].upper() if i % 2 == 0 else x[i].lower()
word = word + c
res.append(word)
return ' '.join(res)- 추가적인 변수 word, res. c를 선언했다.
- append 대신 +를 이용하여 문자열에 변경된 문자를 추가하였다.
- 내 코드 try #5 보다 깔끔하다.
팁
- 변수 명을 길게 씀 -> 정보량 증가, 지면 차지 증가 -> 가독성 저하
- word_list 대신 res, c 등 간결한 변수명을 사용하자.
- 불필요하게 변수를 선언하면 변수의 용도가 겹쳐서 세분화하기 위해 변수명이 길어진다.
- list comprehension을 적극적으로 사용하되, 가독성을 신경 쓰자.
Reference
https://docs.python.org/ko/3/library/stdtypes.html?highlight=split#str.rsplit
다음 섹션에서는 인터프리터에 내장된 표준형에 관해 설명합니다. 기본 내장 유형은 숫자, 시퀀스, 매핑, 클래스, 인스턴스 및 예외입니다. 일부 컬렉션 클래스는 가변입니다. 제자리에서 멤버
docs.python.org
'알고리즘' 카테고리의 다른 글
| [문자열][programmers]문자열 압축 - 2020 KAKAO BLIND RECRUITMENT (0) | 2021.10.07 |
|---|---|
| [문자열][programmers] 문자열 내 마음대로 정렬하기 (0) | 2021.10.05 |
| [문자열][programmers] 문자열 내림차순으로 배치하기 (0) | 2021.10.05 |
| [문자열][programmers] 문자열 다루기 기본 (0) | 2021.10.05 |
| [로드맵] 코딩테스트 학습 개괄 (0) | 2021.10.04 |





